CPU Scheduling in Operating Systems
The CPU can execute only one process at a time, but many processes may need to run. CPU scheduling decides which process will run, when it will run, and for how long.
CPU scheduling is a process used by the operating system to decide which task or process gets to use the CPU at a particular time. This is important because a CPU can only handle one task at a time, but there are usually many tasks that need to be processed. The following are different purposes of a CPU scheduling time.
Why is CPU Scheduling Needed?
CPU scheduling is the process of deciding which process will own the CPU to use while another process is suspended. The main function of CPU scheduling is to ensure that whenever the CPU remains idle, the OS has at least selected one of the processes available in the ready-to-use line.
- Multitasking: Many apps run at once (browser, music player, downloads).
- Efficiency: Keep the CPU busy all the time (no idle CPU).
- Fairness & speed: Give every process a fair share and reduce waiting time.
Terminologies Used in CPU Scheduling.
- Arrival Time: The time at which the process arrives in the ready queue (becomes ready to run). Example- If a user opens a program at 2 ms, its arrival time is 2 ms.
- Completion Time: The time at which the process completes its execution.
- Burst Time: Time required by a process for CPU execution.
- Turn Around Time: Time Difference between completion time and arrival time.
Turn Around Time = Completion Time – Arrival Time
- Waiting Time(W.T): Time Difference between turn around time and burst time.
Waiting Time = Turn Around Time – Burst Time
- Throughput: The number of processes completed per unit time. If 10 processes finish in 1 second, throughput = 10 processes/sec.
Goals of CPU Scheduling
- Max CPU utilization – keep CPU working as much as possible
- Minimize waiting time
- Minimize turnaround time (from submission to completion)
- Minimize response time (for interactive tasks)
- Ensure fairness
Types of CPU Scheduling
There are mainly two types of scheduling methods:
Preemptive Scheduling:
Preemptive scheduling is used when a process switches from running state to ready state or from the waiting state to the ready state. Preemptive scheduling means the operating system can stop (preempt) a running process and switch the CPU to another process if certain conditions occur—like a higher-priority process arriving or a time slice expiring. A running process may be preempted when:
- A higher-priority process enters the ready queue.
- The process’s time quantum (time slice) expires (in Round Robin).
- A system event requires the CPU for an urgent task.
Non-Preemptive Scheduling:
In non-preemptive CPU scheduling, once a process gets the CPU, it keeps it until it finishes or voluntarily waits for I/O. The operating system cannot interrupt or forcefully take back the CPU in the middle of execution. Non-preemptive scheduling means once a process starts on the CPU, it runs to completion or until it waits for I/O.
Advantages
- Simple to implement (less logic than preemptive).
- No overhead of frequent context switching.
- Suitable for batch processing where quick response isn’t critical.
Disadvantages
- Poor responsiveness for interactive tasks (e.g., user interface may freeze).
- Long waiting times if a long process runs first (convoy effect).
- Risk of starvation for short jobs if long ones arrive earlier.
CPU Scheduling Algorithms
The CPU can run only one process at a time (per core), but many processes are waiting in the ready queue. The operating system uses CPU scheduling algorithms to decide which process to run next, and for how long, to make the system fast, fair, and efficient. CPU scheduling algorithms are the rules or methods the OS follows to select and run processes on the CPU.
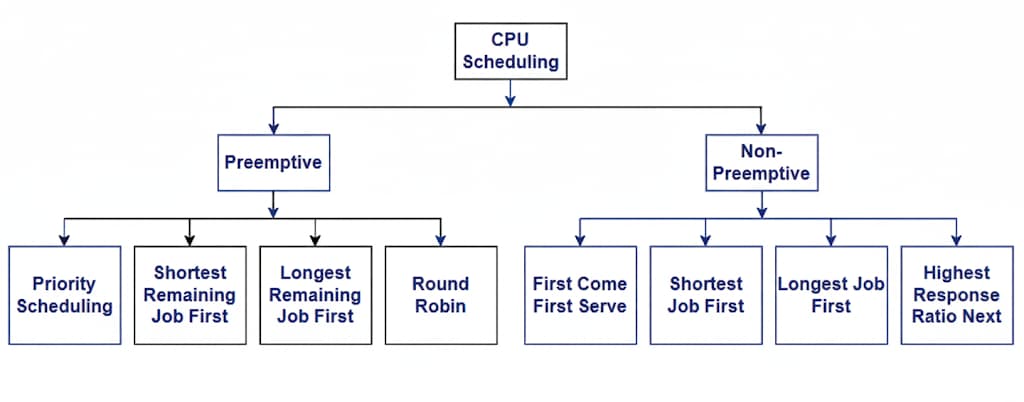
Preemptive Algorithms:
- Priority Scheduling (preemptive)
- Shortest Remaining Time First (SRTF)
- Round Robin (RR)
- Multilevel Feedback Queue
Non-Preemptive Algorithms:
- First Come First Serve (FCFS)
- Shortest Job First (SJF)